
Review of Multithreaded Programming¶
Sum3 Problem Overview¶
Basic Description¶
The Sum3 problem is described by a rather simple question: Given a set of 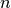 integers, how many triples of distinct elements in that list add up to 0.
integers, how many triples of distinct elements in that list add up to 0.
For example, given the following list:
-1, -2, 0, 2, 3
the answer is 2:
-1 + -2 + 3 = 0
-2 + 0 + 2 = 0
The simplest way to code a solution to the Sum3 problem is to use a double nested looping structure to generate the indices of all possible triples in the input array. Clearly, this is simple to express in code but has an unfortunate time complexity of 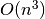 . For example, the following C++ code uses 3
. For example, the following C++ code uses 3 for loops to achieve a correct solution.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | #include <iostream>
using namespace std;
int main( )
{
int dataSize = 5;
int* data = new int[ dataSize ];
data[0] = -1;
data[1] = -2;
data[2] = 0;
data[3] = 2;
data[4] = 3;
// do the naive Sum3 computation. O(n^3)
int count = 0;
for (int i = 0; i < dataSize-2; i++)
for (int j = i+1; j < dataSize-1; j++)
for (int k = j+1; k < dataSize; k++)
if (data[i] + data[j] + data[k] == 0)
count++;
cout<< count <<endl;
}
|
Complete Naive Solution¶
The next code block uses the same solution as above, but includes a command line parameter that will generate an array of random numbers of a user-specified size. The getRandInt() function loads the vector passed into it with random integers. The data vector allocates space for the number of integers required, and is then passed to the getRandInt() function. This version of the program allows the user to get a feel for how an program behaves in practice. Try compiling the program and running it.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 | #include <iostream>
#include <sstream>
using namespace std;
int getRandInt( int* dataVec, int dataSize )
{
// load up a vector with random integers
int num;
for( int i = 0; i < dataSize; i++ ) {
// integers will be 1-100
num = rand() % 100 +1;
if( rand( ) % 2 == 0 ) {
// make some integers negative
num *= -1;
}
dataVec[i] = num;
}
}
int main(int argc, char * argv[] )
{
int dataSize = 0;
if( argc < 2 ) {
std::cerr << "usage: exe [num of nums] [optional seed value]" << std::endl;
exit( -1 );
}
{
std::stringstream ss1;
ss1 << argv[1];
ss1 >> dataSize;
}
if( argc >= 3 ) {
std::stringstream ss1;
int seed;
ss1 << argv[2];
ss1 >> seed;
srand( seed );
}
else {
srand( 0 );
}
// create a data vector
int* data = new int[ dataSize ];
// load it up with random data
getRandInt( data, dataSize );
int *dataPtr = &data[0];
// do the naive Sum3 computation. O(n^3)
int count = 0;
for (int i = 0; i < dataSize-2; i++)
for (int j = i+1; j < dataSize-1; j++)
for (int k = j+1; k < dataSize; k++)
if (dataPtr[i] + dataPtr[j] + dataPtr[k] == 0){
count++;
}
cout<< count <<endl;
}
|
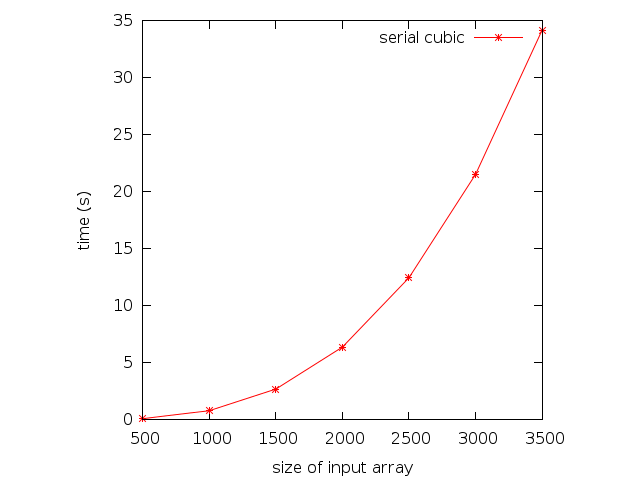
Here are some running times for the previous program:
| Array Size | Time (s) |
|---|---|
| 500 | .106 |
| 1000 | .804 |
| 1500 | 2.698 |
| 2000 | 6.382 |
| 2500 | 12.459 |
| 3000 | 21.519 |
| 3500 | 34.162 |
The running times are plotted. The cubic nature of the curve is clearly visible.
Exercise
Create a Makefile and use the Makefile to compile the program listed above. Run the program using the time command on Linux to see some running times. Collect running times on two different machines. Write a brief report indicating your results and listing the machine specifications. List reasons why one machine is faster than the other.
To find out machine specs on Linux, check out the lspci and lscpu commands, and check out the /proc filesystem. Check the man pages and/or Google for information on how to use/interpret these resources
Sum3 Simple Implementation (Serial)¶
For an input array of arbitrary integers (that is, we make no assumptions as to the range of the integers), Sum3 can be solved in 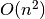 time using relatively simple algorithms.
time using relatively simple algorithms.
The purpose of this chapter is to emphasize the point that parallelism is not always the best solution to a problem. Sometimes, making algorithmic improvements (resulting in better theoretical complexity) can provide better speedups than parallelism, especially if you don’t have the hardware resources to take advantage of a parallel algorithm.
Using a Hash Table¶
The easiest approach to code is to take advantage of hash tables. Hash tables are implemented in many languages, so they are cheap from a coding perspective, and they offer 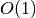 time for inserting an element and determining if an element is in the hash table ... under ideal circumstances. The approach is to:
time for inserting an element and determining if an element is in the hash table ... under ideal circumstances. The approach is to:
- Load all numbers in a hash table
- Generate all possible pairs of numbers
- Check if the negation of the sum of each pair of numbers is in the hash table.
However, this approach suffers from some drawbacks. First, hash table operations can degrade to linear time under certain conditions (although this can be managed rather easily). Second, care must be taken to ensure that unique triples are identified. For example, if the input array was -2, 0, 4, one must ensure that -2+-2+4 = 0 does not get counted as a valid triple (since -2 only appears once in the input).
Using a Sorted Input Array¶
A slightly more complicated algorithm requires that the input array be sorted. The algorithm contains a loop that will traverse the input array from first to last.
Assume a sorted input array array containing n elements. We will first find all triples that add up to 0 and involve the first element in array. We set a=array[0]. A triple is then formed with b=array[0+1] and c=array[n-1]. If a+b+c > 0, then we need to reduce the sum to get it closer to 0, so we set c=array[n-2] (decrease the largest number in the triple to get a smaller sum). If a+b+c < 0, then we need to increase the sum to get it closer to 0, so we set b=array[0+2] (increase the smaller number to get a larger sum). if a+b+c = 0, we have a triple that adds up to 0, and we either set c=array[n-2] or b=array[0+2] in order to test the next triple (in the code below, we set c=array[n-2]). This process continues until b and c refer to the same array element. At the end of this process, all possible triples involving the first array element have been computed.
To compute all triples involving the first array element, we took a pair of numbers from the array. After examining the pair, one number was excluded from further consideration in future triples involving the first array element. Therefore, for n array elements, we will construct n-2 triples due to the following: the first array element is used in every triple, leaving us to create pairs of the remaining n-1 elements; the first pair uses two elements and eliminates one from further consideration; all following pairs will reuse 1 element from the previous pair, and eliminate one element from consideration. Thus, computing all triples involving a single element requires 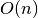 time. Repeating this for
time. Repeating this for n elements in the input array requires time. A C++ implementation of this algorithm follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 | #include <iostream>
#include <sstream>
using namespace std;
int getRandInt( int *dataVec, int dataSize )
{
// load up a vector with random integers
int num;
for( int i = 0; i < dataSize; i++ ) {
// integers will be 1-100
num = rand() % 100+1;
if( rand( ) % 2 == 0 ) {
// make some integers negative
num *= -1;
}
dataVec[i] = num;
}
}
int main(int argc, char * argv[] )
{
int dataSize = 0;
if( argc < 2 ) {
std::cerr << "usage: exe [num of nums] [optional seed value]" << std::endl;
exit( -1 );
}
{
std::stringstream ss1;
ss1 << argv[1];
ss1 >> dataSize;
}
if( argc >= 3 ) {
std::stringstream ss1;
int seed;
ss1 << argv[2];
ss1 >> seed;
srand( seed );
}
else {
srand( 0 );
}
// create a data vector
int *data = new int[ dataSize ];
// load it up with random data
getRandInt( data, dataSize );
// sort the data
sort( data, data + dataSize );
// do the Sum3 computation. O(n^2)
int count = 0;
int a,b,c, sum; // array elements
int j,k; // array indices
for (int i = 0; i < dataSize-2; i++){
a = data[i];
j = i+1;
k = dataSize-1;
while( j < k ) {
b = data[j];
c = data[k];
sum = a+b+c;
if( sum == 0 ){
cerr << a << " " << b << " " << c << endl;
count++;
}
if( sum < 0 ){
j++;
}
else {
k--;
}
}
}
cout<< count <<endl;
|
}
One pitfall in this algorithm is that duplicate values cause problems.
Example
Consider the input string array = [-4, 1, 1, 3, 3]. There are 4 triples that sum to 0:
array[0] + array[1] + array[3] = 0array[0] + array[1] + array[4] = 0array[0] + array[2] + array[3] = 0array[0] + array[2] + array[4] = 0However, the above code will only find 2 triples. The algorithm progresses as follows, with items being examined in bold:
Effectively, the algorithm only finds triples involving the first 1, and none involving the second 1.
In fact, duplicates cause 3 problems that must be addressed:
- 3 or more 0s will independently sum to 0. In fact, for
n > 20s, there will ben choose 3triples that sum to 0. - A sequence of repeating numbers exists such that a pair of those numbers along with a third forms a triple that sums to 0. For example: `` -4, 1, 2, 2, 2`` contains 3 triples that sum to 0. When such a sequence is detected with length
n > 2, there will ben choose 2triples that sum to 0. Note that a correct handling of this case can also handle the case where 3 or more 0s exist. - The situation in the above example when two sequences of repeating numbers exist such that the repeated element of each sequence along with a third number not equal to those elements sum to 0. For sequences of non-equal numbers
xandywith respective lengthsm >= 1andn >= 1, such that there exists a numberz | x+y+z = 0, there will bex*ytriples that sum to 0 for each individual copy ofz.
The following program handles duplicates correctly. Problem 1 and Problem 2 are handled in a single conditional, the first if statement in the while loop. Note that when such a situation occurs, we have effectively found the point at which j and k converge, and so we break out of the while loop. Problem 3 is handled in the second if statement in the while loop; the modification of j and k are again handled specially in this situation (since they may be increased or decreased by more than 1). The third if statement in the while loop handles the situation in which duplicates do not occur. The final else block in the while loop handles the normal increment of j or decrement of k when a triple with a non-zero sum is visited. The complete solution for handling duplicates is:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 | #include <iostream>
#include <sstream>
using namespace std;
int getRandInt( int *dataVec, int dataSize )
{
// load up a vector with random integers
int num;
for( int i = 0; i < dataSize; i++ ) {
// integers will be 1-100
num = rand() % 100 +1;
if( rand( ) % 2 == 0 ) {
// make some integers negative
num *= -1;
}
dataVec[i] = num;
}
}
int main(int argc, char * argv[] )
{
int dataSize = 0;
if( argc < 2 ) {
std::cerr << "usage: exe [num of nums] [optional seed value]" << std::endl;
exit( -1 );
}
{
std::stringstream ss1;
ss1 << argv[1];
ss1 >> dataSize;
}
if( argc >= 3 ) {
std::stringstream ss1;
int seed;
ss1 << argv[2];
ss1 >> seed;
srand( seed );
}
else {
srand( 0 );
}
// create a data vector
int *data = new int[ dataSize ];
// load it up with random data
getRandInt( data, dataSize );
// sort the data
sort( data, data + dataSize );
// do the Sum3 computation. O(n^2)
int count = 0;
int a,b,c, sum; // array elements
int j,k; // array indices
for (int i = 0; i < dataSize-2; i++){
a = data[i];
j = i+1;
k = dataSize-1;
while( j < k ) {
b = data[j];
c = data[k];
sum = a+b+c;
if( sum == 0 && b == c ) {
// case where b == c. ie, -10 + 5 + 5
// or where a == b == c == 0
int num = k-j+1;
count += (num*(num-1))/2;
break;
}
else if( sum == 0 && (data[j+1] == b || data[k-1] == c )){
// case where there are multiple copies of b or c
// find out how many b's and c's there are
int startj = j;
while( data[j+1] == b ) j++;
int startk = k;
while( data[k-1] == c ) k--;
count += (j-startj+1) * (startk-k+1);
j++;
k--;
}
else if( sum == 0 ){
// normal case
count++;
j++;
} else {
// if sum is not 0, increment j or k
if( sum < 0 ) j++;
else k--;
}
}
}
cout<< count <<endl;
}
|
Here are some running times for the previous program:
| Array Size | Time (s) |
|---|---|
| 500 | .005 |
| 1000 | .008 |
| 1500 | .013 |
| 2000 | .019 |
| 2500 | .026 |
| 3000 | .033 |
| 3500 | .043 |
| 4000 | .054 |
| 10000 | .299 |
| 20000 | 1.142 |
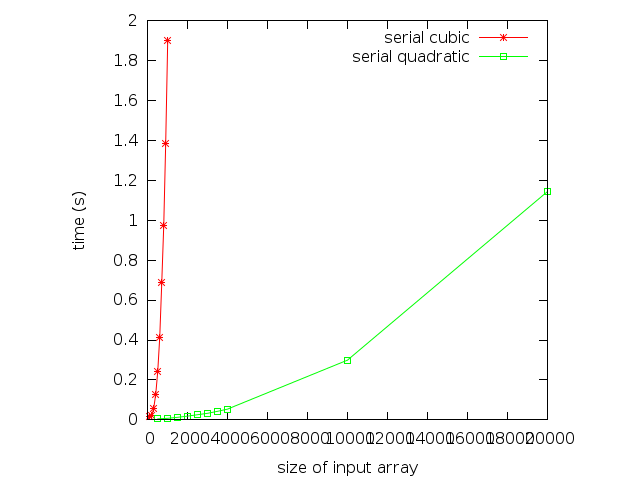
Here we show the graph of running times for the cubic and quadratic versions of the algorithm. Notice the vast difference in running times for the two programs. Again, the cubic and quadratic nature of the algorithms are visible.
Exercise
Create a Makefile and use the Makefile to compile the program listed above. Run the program using the time command on Linux to see some running times. Collect running times on two different machines. Write a brief report indicating your results and listing the machine specifications. List reasons why one machine is faster than the other.
To find out machine specs on Linux, check out the lspci and lscpu commands, and check out the /proc filesystem. Check the man pages and/or Google for information on how to use/interpret these resources.
Sum3 Parallel Implementation with Pthreads and OpenMP¶
At this point we have seen two possible algorithms and implementations for the Sum3 problem
- A algorithm that is extremely easy to implement, but that suffers from poor execution time.
- A algorithm that is much faster in terms of execution time, but that requires care to handle sequences of repeating values correctly.
The question now is whether or not we can do better. It turns out that algorithmically, we cannot...at least not yet; there are currently no known algorithms to solve the Sum3 problem faster than time. In fact, a class of problems exists called Sum3 hard problems [GOM1995CG]. Any problem that is constant time reducible to a Sum3 problem is Sum3-hard; the implication being that a sub-quadratic time solution to any problem in the Sum3-hard class provides a sub-quadratic time solution to Sum3.
Introducing Parallelism with Multiple Threads¶
In terms of running time, we can do better with the Sum3 problem. One way to improve running time is to utilize a multi-core CPU with a multi-threaded program. The general approach is to divide the work that must be completed among multiple cores. Ideally, if we evenly divide the work among two processors, the program should run twice as fast. Another way to express this is to say that the program should have a 2x speedup over the serial version. The concept of speedup is a useful measure to gauge the effectiveness of a particular optimization, and is defined as follows:
Definition
Let 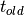 be the running time of a program and
be the running time of a program and 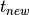 be the running time of the same program that has been optimized. The speedup of the new program is equal to the running time of the old program divided by the running time of the new program:
be the running time of the same program that has been optimized. The speedup of the new program is equal to the running time of the old program divided by the running time of the new program:
speedup 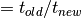
Design of a Multi-Threaded Algorithm¶
Designing a multi-threaded program, or a parallel algorithm for that matter, requires a different thought process than defining a serial program. When defining a serial algorithm, the focus is usually to determine the steps that must be completed in succession to achieve an answer. When developing a multi-threaded program, one must think in terms of how the work can be divided among threads. It is sometimes useful to begin with a serial program and try to modify it to divide work, and other times it is easier to simply start from scratch.
Concept
How should the work be divided among threads?
In order to effectively parallelize work, each thread must be able to do a portion of the work. Ideally, each thread will take roughly the same amount of time to execute; it is generally undesirable for a bunch of threads to complete their work quickly and sit around waiting on a single, slow thread to finish.
Lets take the cubic version of the Sum3 algorithm as an example (the core of the program is listed below). The main work of the program consists of the double nested loops that generate all possible triples of numbers from the input array. A reasonable method of dividing the work is to make 2 threads such that each thread generates roughly half of the triples that must be tested. We can achieve this by modifying the outer loop such that one thread will only compute triples in which the first number in the triple comes from the first half the array, and the second thread will compute triples in which the first number comes from the second half of the array. Such a modification requires minor changes to the core of the program.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | #include <iostream>
using namespace std;
int main( )
{
int dataSize = 5;
int* data = new int[ dataSize ];
data[0] = -1;
data[1] = -2;
data[2] = 0;
data[3] = 2;
data[4] = 3;
// do the naive Sum3 computation. O(n^3)
int count = 0;
for (int i = 0; i < dataSize-2; i++)
for (int j = i+1; j < dataSize-1; j++)
for (int k = j+1; k < dataSize; k++)
if (data[i] + data[j] + data[k] == 0)
count++;
cout<< count <<endl;
}
|
Cubic Sum3 Using Pthreads¶
Pthreads are a low level threading mechanism that have been around for a long time. Pthreads are provided by a C library, and as such, they do things in a very old-school, C way of thinking. The basic idea is that the programmer defines a function, and then tells the pthread library to create a thread to run that function. Therefore, we have a concept of a master thread, which is the thread of the program that is started when the program is initially executed, and the concept of worker threads, which are spawned by the master thread. Typically, the master thread will spawn some worker threads, and then wait for them to complete before moving on, as illustrated in the following:
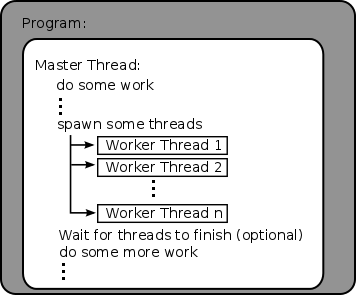
In order to achieve a pthread version of the program, we must first put the code that each thread will execute into a function. We will then call a pthread library call and tell it to use that function as the code the thread will run. The pthread library will then launch the thread. Our master thread can then launch additional threads, do other work, or wait on the launched threads to finish executing. Here are the function calls we will use... you should check your system’s man pages for the most up to date information.
Pthread Library Calls
int
pthread_create(pthread_t *restrict thread, const pthread_attr_t *restrict attr,
void *(*start_routine)(void *), void *restrict arg);
Create a thread. The first argument will be assigned a pointer to a thread handle that is created. The second argument is a pointer to a thread attributes struct that can define attributes of the thread; we will simply pass a NULL to use defaults. The third argument is the function pointer to the function that this thread will execute. The final pointer is a pointer to a single argument that will be passed to the function. Note, to use the argument, the function must type cast it to the appropriate type. Also, if more than 1 arguments are required, you must pack them into a struct.
Returns a 0 on success, a non-zero error code on failure
int
pthread_join(pthread_t thread, void **value_ptr);
Join a thread. The join command will cause the calling thread to wait until the thread identified by the thread handle in the first argument terminates. We will pass NULL as the second argument.
Returns a 0 on success, a non–zero error code on failure
Now that we have the ability to create and join threads, we can create a simple pthread program. The following example shows how to create threads to do some work, and pass arguments to them. Remember that pthreads require the function that will be executed as a thread to take a single argument; so we must wrap all the arguments we want to pass to the function into a single struct. We define the struct on line 23, and instantiate two instances of the struct on line 87. Because a pointer to the struct is passed to our partial3SumThread function as a void *, we must cast the pointer back to the correct type on line 33 before we can use it in the function.
We want to pass the input array to each thread, so we can simply pass it to the function.
Note
The function launched as a thread by the pthread library must take a single argument of type void pointer. This argument must be type-cast to a void to pass it into the function, and type-cast back to its original type within the function. Of course, this breaks type checking for the compiler, so be careful and double check the types yourself!
Here is the code:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 | #include <iostream>
#include <sstream>
using namespace std;
int getRandInt( int *dataVec, int dataSize )
{
// load up a vector with random integers
int num;
for( int i = 0; i < dataSize; i++ ) {
// integers will be 1-100
num = rand() % 100 +1;
if( rand( ) % 2 == 0 ) {
// make some integers negative
num *= -1;
}
dataVec[i] = num;
}
}
// define a struct to pass information to the threads
struct threadInfo{
int myID;
int *dataPtr;
int dataSize;
int count;
};
void* partial3SumThread( void* arg ) {
// type cast the argument back to a struct
threadInfo * myInfo = static_cast<threadInfo*>( arg );
// each thread only works on half the array in the outer loop
// compute the bounds based on the ID we assigned each thread.
// remember, we only have 2 threads in this case, so we will hard code a 2
int start = ((myInfo->dataSize / 2) * myInfo->myID );
int stop = ((myInfo->dataSize / 2)* (myInfo->myID+1));
if( myInfo->myID == 1 )
stop =myInfo->dataSize-2;
// do the naive Sum3 computation. O(n^3)
for (int i = start; i < stop; i++)
for (int j = i+1; j < myInfo->dataSize-1; j++)
for (int k = j+1; k < myInfo->dataSize; k++)
if (myInfo->dataPtr[i] + myInfo->dataPtr[j] + myInfo->dataPtr[k] == 0){
myInfo->count++;
}
}
int main(int argc, char * argv[] )
{
int dataSize = 0;
if( argc < 2 ) {
std::cerr << "usage: exe [num of nums] [optional seed value]" << std::endl;
exit( -1 );
}
{
std::stringstream ss1;
ss1 << argv[1];
ss1 >> dataSize;
}
if( argc >= 3 ) {
std::stringstream ss1;
int seed;
ss1 << argv[2];
ss1 >> seed;
srand( seed );
}
else {
srand( 0 );
}
// create a data vector
int *data = new int[ dataSize ];
// load it up with random data
getRandInt( data, dataSize );
// allocate thread handles
pthread_t worker1tid, worker2tid;
// allocate and set up structs for 2 threads
threadInfo info1, info2;
info1.myID = 0;
info1.dataPtr = data;
info1.dataSize = dataSize;
info1.count = 0;
info2.myID = 1;
info2.dataPtr = data;
info2.dataSize = dataSize;
info2.count = 0;
// allocate space for a return value
int returnVal;
// call the worker threads
if ( returnVal = pthread_create( &worker1tid, NULL, partial3SumThread, &info1 ) ) {
cerr<< "pthread_create 1: "<< returnVal <<endl;
exit( 1 );
}
if ( returnVal = pthread_create( &worker2tid, NULL, partial3SumThread, &info2 ) ) {
cerr<< "pthread_create 2: "<< returnVal <<endl;
exit( 1 );
}
// now wait on the threads to finish
if ( returnVal = pthread_join( worker1tid, NULL ) ) {
cerr<< "pthread_join 1: "<< returnVal <<endl;
exit( 1 );
}
if ( returnVal = pthread_join( worker2tid, NULL ) ) {
cerr<< "pthread_join 2: "<< returnVal <<endl;
exit( 1 );
}
cout<< info1.count + info2.count <<endl;
}
|
The program has a relatively simple structure; the core of the Sum3 computation is done in the partial3SumThread function. 2 instances of the function are launched, and we assign the first instance an ID of 0, and the second instance an ID of 1. These thread IDs are manually assigned and stored in a threadInfo struct that we create. The structs are created and initialized on lines 87-95. Based on the thread’s ID, we determine which half of the array a thread should use in the outer loop of the Sum3 computation (lines 39-42). A thread is launched on line 99 and line 103. Once all the threads are launched, the main thread must wait for them to complete before printing the result, so the main thread calls one join function for each thread (lines 108 and 113). Once all worker threads have joined, we print the result.
Here are some running times on a machine with a 2 core cpu, and the results graphed along with the serial and serial quadratic versions of the algorithm:
| Array Size | Time (s) |
|---|---|
| 100 | .01 |
| 200 | .019 |
| 300 | .029 |
| 400 | .063 |
| 500 | .125 |
| 600 | .207 |
| 700 | .324 |
| 800 | .475 |
| 900 | .668 |
| 1000 | .912 |
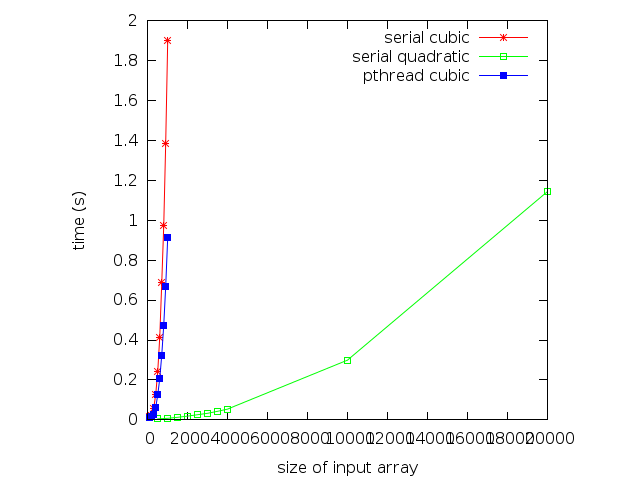
The pthreads version is clearly faster. As expected, the version with two threads runs roughly twice as fast as the version with 1 thread. For an array of 500, the speedup is 1.9, for an array of 1000, the speedup is 2.08. A speedup of more than 2 is likely due to timing granularity. The Linux time command was used, which is not the most accurate time keeping method. Other considerations should have an impact. For example, the two threads could have an effect on cache, causing a greater amount of cache hits or misses than the single threaded version. Cache misses cause the processor to stall, wasting time. More cache hits means the processor stalls less, and does the work in a shorter amount of time.
Exercise
The pthreads version of the Sum3 problem is hard coded to handle 2 threads. Convert the program such that it will take the number of threads to use as a command line argument, and then generate that many threads. Hint: you will have an easier time of it if you use vectors to hold all thread information. For example, you will have a vector of threadInfo structs, one for each thread.
Thread Communication¶
In the pthreads version of Sum3, very little thread communication took place. In fact, the only thread communication that happened was the master thread provided some data to the worker threads in the form of a function argument. Usually, threads will communicate with each other through shared memory. The key to understanding shared memory is understanding scoping rules. Basically, a thread will have access to all memory locations that are in scope for that thread, and all memory locations accessible through pointers that are in scope for that thread. This means that if a variable has global scope, then ALL threads will be able to read and write to it. This means, two threads can communicate by reading and writing to such a variable. In our program above, we declared two instances of the threadInfo struct in the main() function (line 87); those instances are info1, info2. Those structs now exist in memory, but the names info1, info2 exist in scope for the main() function. We store information that the threads need in those structs. To provide access to that information, we pass the pointer to one of those structs to each thread during the pthread_create call. This means that a thread can access its struct through that pointer. Essentially, the master thread has communicated with the worker threads, letting them know their thread ID, the input array, etc.
Note that in the program, only 1 copy of the data array exists. It is created in the main() function. Pointers to that array are stored in the threadInfo structs, so that each thread can access the same array. This does not cause any problems because both threads only read the array, they are not making changes to it. Also note that each struct has its own memory location to store a count. Thus, each thread is keeping track of its own count. This is why all the count values from the threadInfo structs must be summed in line 119.
Exercise
Change the pthreads Sum3 program such that both threads access the same memory location for keeping track of their count variable. Don’t use any other pthread library features. Run the program multiple times. What happens to the result value? why?
Doing Things a Little Differently with OpenMP¶
Pthreads is just one method to create multi-threaded programs. Most languages have some built-in mechanism or library to launch threads. Another mechanism in C/C++ is OpenMP. One drawback to pthreads is that although the core Sum3 computation changed very little in the pthread program, the program did require some somewhat significant structural changes. Recall that we had to put our computation into a function, set up a struct to pass data to the function, introduce create and join function calls, etc. Furthermore, we only implemented 2 threads; implementing more threads requires even more work. So, there is some programming overhead to converting a serial program to a parallel program using pthreads.
OpenMP takes a compiler-based approach to threading. Instead of inserting function calls and re-organizing code to create threads, OpenMP requires you to place compiler directives near portions of code that will be run in parallel so the compiler can generate a team of threads. These directives are known as pragmas. One of the goals of OpenMP is to provide a mechanism whereby serial code can be parallelized using multiple threads with only minor code modifications. The result is that you can write a serial program, debug it while it is serial (a much easier task than debugging parallel code), and then simply add a pragma to achieve parallelism using multiple threads.
As an example, we will write a OpenMP version of the Sum3 problem with a similar structure as the pthread version: we will create 2 threads, and each thread will only iterate over a portion of the outer loop. We will need the following OpenMP pragmas and functions:
OpenMP Interface
1 2 3 4 | #pragma omp parallel
{
// some code
}
|
Will create a team of n threads where n is the number of computational cores available on the computer on which this code is executed. Each thread will execute the code in the code block. No code will be executed beyond the code block until all threads have joined.
1 | int omp_get_thread_num();
|
Returns the unique thread identifier of the thread that executes this function. If only a single thread exists, the function always returns 0. If multiple threads exist, the function returns a number in the range from 0 to omp_get_num_threads()-1, inclusive.
1 | int omp_get_num_threads();
|
Returns the number of threads in the current team. If only 1 thread exists (the serial portion of the code), it returns 1.
1 | void omp_set_num_threads( int num_threads );
|
Sets the default number of threads to create in subsequent parallel sections (for example, sections defined by #pragma omp parallel).
1 | g++ -fopenmp source.cpp
|
remember to use the OpenMP compiler flag to compile programs using OpenMP.
With these pragmas and functions, we can duplicate the pthreads version of the program by forcing 2 threads to operate on the data. We will call omp_set_num_threads(2) (line 57, below) to force 2 threads, then break up the work similarly to what we did before. Much like pthreads, OpenMP threads will communicate through memory locations; again, scoping rules apply: (1) any variable whose scope is external to a parallel section will be shared among all threads, and (2) all threads will have their own private copy of any variable declared within the scope of a parallel section. So, we will define an integer for each thread to keep track of the number of triples summing to 0 that it sees external to the parallel section, so we can add those counts together at the end (lines 54-55). Recall in the pthread code, we had to explicitly set thread identifiers to 0 and 1; OpenMP will do this for us and each thread can find its ID using the omp_get_thread_num() function (line 62):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 | #include <iostream>
#include <sstream>
#include <omp.h>
using namespace std;
int getRandInt( int *dataVec, int dataSize )
{
// load up a vector with random integers
int num;
for( int i = 0; i < dataSize; i++ ) {
// integers will be 1-100
num = rand() % 100 +1;
if( rand( ) % 2 == 0 ) {
// make some integers negative
num *= -1;
}
dataVec[i] = num;
}
}
int main(int argc, char * argv[] )
{
int dataSize = 0;
if( argc < 2 ) {
std::cerr << "usage: exe [num of nums] [optional seed value]" << std::endl;
exit( -1 );
}
{
std::stringstream ss1;
ss1 << argv[1];
ss1 >> dataSize;
}
if( argc >= 3 ) {
std::stringstream ss1;
int seed;
ss1 << argv[2];
ss1 >> seed;
srand( seed );
}
else {
srand( 0 );
}
// create a data vector
int *data = new int[ dataSize ];
// load it up with random data
getRandInt( data, dataSize );
// do the naive Sum3 computation. O(n^3)
int count1 = 0;
int count2 = 0;
omp_set_num_threads( 2 );
#pragma omp parallel
{
int count = 0;
int myID = omp_get_thread_num();
// each thread only works on half the array in the outer loop
// compute the bounds based on the ID we assigned each thread.
// remember, we only have 2 threads in this case, so we will hard code a 2
int start = (( dataSize / 2) * myID );
int stop = ((dataSize / 2)* (myID+1));
if( myID == 1 )
stop =dataSize-2;
for (int i = start; i < stop; i++)
for (int j = i+1; j < dataSize-1; j++)
for (int k = j+1; k < dataSize; k++)
if (data[i] + data[j] + data[k] == 0){
count++;
}
if( myID == 0 )
count1 = count;
else
count2 = count;
}
cout<< count1 + count2 <<endl;
}
|
Now, some running times. Again, speedup is roughly 2 for the OpenMP version, but the OpenMP version required much less code reorganization to implement. The running times are a few thousandths of a second higher than the pthread versions. This is due to a different implementation of threading. In OpenMP, the compiler implements the threading, rather than OS system calls. Because of this, the threads get compiled a little differently. Also, different OpenMP compilers will have slightly different performance results.
| Array Size | Time (s) |
|---|---|
| 100 | .005 |
| 200 | .014 |
| 300 | .032 |
| 400 | .066 |
| 500 | .124 |
| 600 | .212 |
| 700 | .333 |
| 800 | .492 |
| 900 | .696 |
| 1000 | .952 |
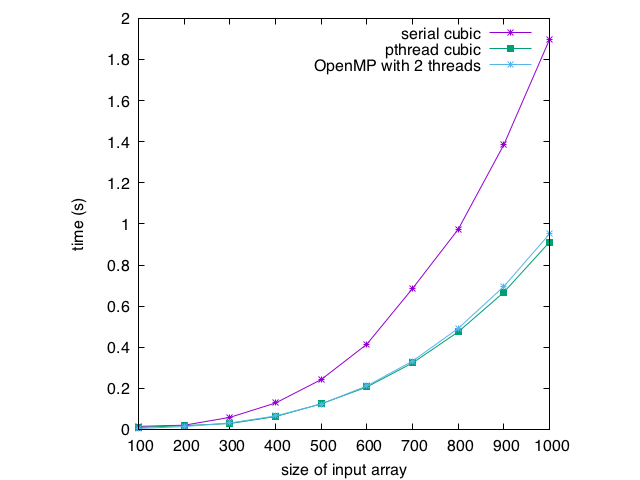
Exercise
Compile the serial cubic version of the program and the OpenMP version with compiler optimizations turned on (for example, use the -O3 with the gcc or g++ compilers). How do the running times compare then?
Creating a Lot of Threads¶
Because OpenMP is integrated into the compiler, the overhead of creating threads is small; thus, it is possible to create many more threads than available processor cores. An important concept of OpenMP is the idea of worker threads: on a computer with 2 cores, the number of worker threads typically defaults to 2 (there are system parameters that control the default settings). Even if many threads are created, only 2 will be able to run at any given time. Therefore, it is acceptable, although not always optimal, to create many more threads than there are processors available. One easy way to create a lot of threads is through the omp parallel for pragma. This pragma must be placed directly before a for loop. OpenMP will then treat each iteration of the loop as a block of work that can be assigned to a worker thread; therefore, if you have 10 worker threads and 10 loop iteration, all iterations can be run in parallel on individual worker threads. If there are 10 worker threads and 11 iterations, one worker thread will effectively run two loop iterations, but those iterations are still treated as separate blocks of work; one thread simply picks up the extra block of work when it finishes its first block. To be safe, make sure that the for loop contains the declaration of the looping variable (this will be more clear when we talk about shared memory below)!
One problem with generating lots of threads is that we also need to then generate lots of count variables (lines 54-55 above). One alternative is to create a single global count variable, but then make sure that only 1 thread accesses it at a time. To ensure that only 1 thread accesses a variable at a time, we put that variable access in a critical section using an OpenMP omp_critical pragma. Anything in a code block directly following an omp_critical pragma is guaranteed to be accessed by exactly 1 thread at a time. Using these directives, our multi-threaded code looks very similar to our original code:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 | #include <iostream>
#include <sstream>
#include <omp.h>
using namespace std;
int getRandInt( int * dataVec, int dataSize )
{
// load up a vector with random integers
int num;
for( int i = 0; i < dataSize; i++ ) {
// integers will be 1-100
num = rand() % 100 +1;
if( rand( ) % 2 == 0 ) {
// make some integers negative
num = num * -1;
}
dataVec[i] = num;
}
}
int main(int argc, char * argv[] )
{
int dataSize = 0;
if( argc < 2 ) {
std::cerr << "usage: exe [num of nums] [optional seed value]" << std::endl;
exit( -1 );
}
{
std::stringstream ss1;
ss1 << argv[1];
ss1 >> dataSize;
}
if( argc >= 3 ) {
std::stringstream ss1;
int seed;
ss1 << argv[2];
ss1 >> seed;
srand( seed );
}
else {
srand( 0 );
}
// create a data vector
int * data = new int[ dataSize ];
// load it up with random data
getRandInt( data, dataSize );
int count = 0;
// do the naive Sum3 computation. O(n^3)
#pragma omp parallel for
for (int i = 0; i < dataSize-2; i++)
for (int j = i+1; j < dataSize-1; j++)
for (int k = j+1; k < dataSize; k++)
if (data[i] + data[j] + data[k] == 0){
#pragma omp critical
{
count++;
}
}
cout<< count <<endl;
}
|
The one drawback of the critical section is that execution may serialize on it. Therefore, if every thread enters the critical section in every execution of the loop, then the program will behave much like a serial program in terms of running time. Therefore, placement of the critical section is important! Note that we placed it inside the if statement. Every triple must be tested to see if it sums to 0, but only a small portion of the triples actually sum to 0. If we placed the if statement in the critical section, we would get serial behavior. If every triple summed to 0 (an array of lots of 0s), we would also get serial behavior (regardless of the placement of the critical section with respect to the if statement). Thus, the previous method will have more reliable speedups in these edge cases, but this method will get speedups for input that we are likely to see, and requires only a few lines of modification to the code, and no logic changes!
Here are the running times. Note that the critical section does have an impact, but it is not too bad. A speedup of 1.9 vs 1.9 for the pthreads version at an array size of 500 (the same!), and a speedup of 1.9 vs 2.1 for the pthreads version at an array size of 1000:
| Array Size | Time (s) |
|---|---|
| 100 | .005 |
| 200 | .014 |
| 300 | .032 |
| 400 | .068 |
| 500 | .130 |
| 600 | .218 |
| 700 | .343 |
| 800 | .512 |
| 900 | .722 |
| 1000 | .989 |
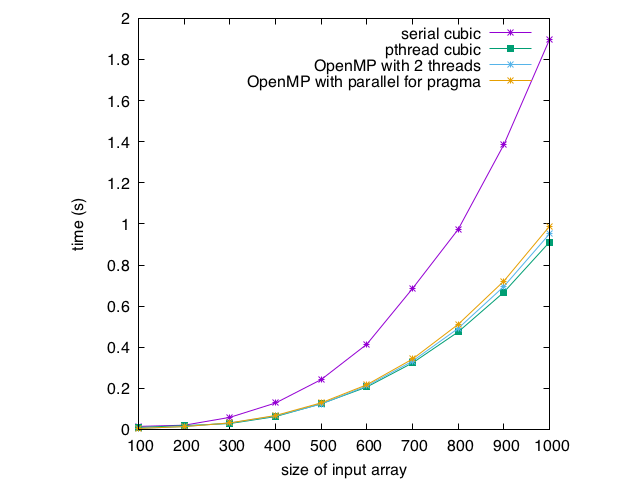
Exercise
Change the OpenMP program using a critical section to serialize in 2 ways. First, use an input array of all 0’s. Then move the critical section to contain the if statement. Compare running times to the serial version of the algorithm (the cubic one), and give a list of reasons as to why one is faster/slower than the other.
Reductions¶
OpenMP has a lot of other options, constructs, and functionality. Check the official documentation for more details [OpenMPDoc]. One of the advantages of OpenMP is that many of these constructs make it very easy to achieve tasks that one has to do manually with pthreads. A good example of this is the reduction.
A reduction simply means to combine many values into a single value using a specified operator. For example, we can reduce an array of numbers to a single sum of all the numbers in the array (by adding them up). Alternatively, we could reduce an array to its max or min value, by searching for the largest or smallest value, respectively, in the array. We can use a reduction to completely get rid of the critical section in the previous version of the code.
When declaring an omp parallel for pragma, we can identify values that will be reduced after all threads have executed. Each thread will then make its own local copy of any variable specified in a reduction, and OpenMP will automatically perform the specified reduction of all of those local variables into a single value. The reduction operation is also specified.
For example, to get rid of the critical section above, we should tell OpenMP to perform a reduction on count. Thus, every thread will get its own copy of count. We will specify a sum reduction, so that at the end of thread execution, all the local versions of the count variable get summed into a single variable. The result is that we only have to add a single line of code to achieve parallel implementation of Sum3. Line 55 specifies that a sum reduction on the variable count will be computed:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 | #include <iostream>
#include <sstream>
#include <omp.h>
using namespace std;
int getRandInt( int *dataVec, int dataSize )
{
// load up a vector with random integers
int num;
for( int i = 0; i < dataSize; i++ ) {
// integers will be 1-100
num = rand() % 100 +1;
if( rand( ) % 2 == 0 ) {
// make some integers negative
num *= -1;
}
dataVec[i] = num;
}
}
int main(int argc, char * argv[] )
{
int dataSize = 0;
if( argc < 2 ) {
std::cerr << "usage: exe [num of nums] [optional seed value]" << std::endl;
exit( -1 );
}
{
std::stringstream ss1;
ss1 << argv[1];
ss1 >> dataSize;
}
if( argc >= 3 ) {
std::stringstream ss1;
int seed;
ss1 << argv[2];
ss1 >> seed;
srand( seed );
}
else {
srand( 0 );
}
// create a data vector
int *data = new int[ dataSize ];
// load it up with random data
getRandInt( data, dataSize );
int count = 0;
// do the naive Sum3 computation. O(n^3)
#pragma omp parallel for reduction(+:count)
for (int i = 0; i < dataSize-2; i++)
for (int j = i+1; j < dataSize-1; j++)
for (int k = j+1; k < dataSize; k++)
if (data[i] + data[j] + data[k] == 0){
count++;
}
cout<< count <<endl;
}
|
And finally, here are some running times:
| Array Size | Time (s) |
|---|---|
| 100 | .005 |
| 200 | .013 |
| 300 | .031 |
| 400 | .068 |
| 500 | .125 |
| 600 | .213 |
| 700 | .332 |
| 800 | .505 |
| 900 | .697 |
| 1000 | .963 |
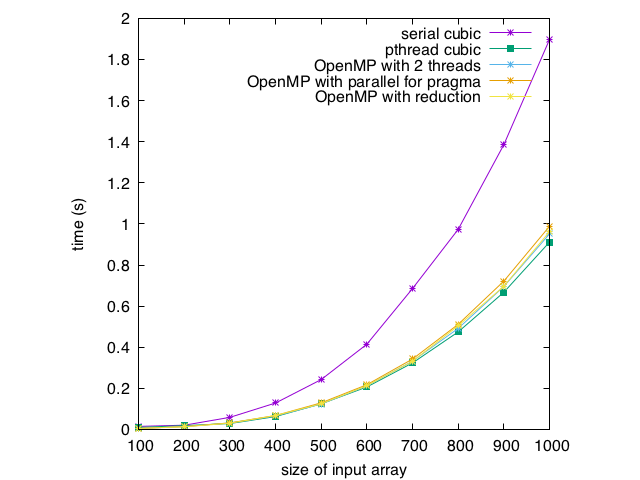
The running times are a bit slower than the pthreads version, and a bit faster than the OpenMP version with a critical section. However, remember that the pthreads version is hard coded to 2 threads, and the programmer essentially must implement their own reduction if you want to use more threads. This version required adding 1 pragma to an otherwise unchanged serial implementation and achieved threading that will automatically scale to the number of available processors with NO extra work! This code is easy to debug (you simply comment out the pragma and debug in serial, or compile without the OpenMP flag and the pragmas should be ignored), uses advanced features, and is easily adaptable to multiple hardware configurations. This should convince you of why OpenMP is a popular choice for threading.
Exercise
Look at the scheduling clauses for OpenMP (the wiki has a concise description [OpenMPWiki]). Try dynamic scheduling with various chunk sizes on the above program. Report the effects on execution time, and describe why those effects are occurring.
Convert the version of the algorithm to a parallel algorithm using OpenMP. Try to get the fastest time for 100,000 numbers. Make sure to use a computer with multiple cores (and hyperthreading turned off!)
| [GOM1995CG] |
|
 problems in computational geometry”, Computational Geometry: Theory and Applications, 1995, 5 (3): 165–185, doi:10.1016/0925-7721(95)00022-2.
problems in computational geometry”, Computational Geometry: Theory and Applications, 1995, 5 (3): 165–185, doi:10.1016/0925-7721(95)00022-2.| [OpenMPDoc] | http://openmp.org/ |
| [OpenMPWiki] | https://en.wikipedia.org/wiki/OpenMP |
This material is based upon work supported by the National Science Foundation under Grant Numbers 1258604 and 1347089. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation