
Introduction to the MapReduce Model of Parallelism¶
Preliminaries¶
Creator Name: Mark McKenney
Content Title: Introduction to the MapReduce Model of Parallelism
Learning Objectives:
- Describe the basic ideas of the mapReduce paradigm
- Be able to construct mapReduce computations in scripting languages
- Gain basic skills in: using the command line interface for MongoDB, loading a data set into MongoDB, performing basic queries to explore aspects of that data set.
- Describe the basic architecture of a mapReduce system.
- Describe the implications of adding/removing hardware to a mapReduce system.
- Describe the data model of a Mongo/BigTable/Hive type system.
- Be able to construct and execute a mapReduce porgram on MongoDB
- Be able to perform queries to explore the result of a mapReduce query.
The mapReduce Paradigm¶
Section Goals:
- Describe the basic ideas of the mapReduce paradigm
- Be able to construct mapReduce computations in scripting languages
The original concept of mapReduce has its roots in functional programming. Basically, a map will apply a function to a set of input data, transform this data in some way, and emit the transformed data. A reduce will apply a function to a set of input data, and essentially combine that input data in some way so that it returns a smaller set of output data. Lets see an example:
Example
The following python program contains a map function that applies a function to each element of a list that will increment that element. The reduce function then sums the elements. The function being applied in the map is an anonymous function (i.e., a function that has no name and is not formally declared in an outer scope. So, the function is only defined for this line of code). The lambda function in the map takes one argument x and increments it, returning the incremented value. Similarly, the lambda function in the reduce takes two arguments, x and y, and returns their sum.
>>> newNums = map( lambda x:x+1, nums )
>>> print newNums
[2, 3, 4, 5, 6]
>>> sum = reduce( lambda x,y: x+y, newNums )
>>> print sum
20
Notice that the lambda function in the map operates on a single item of the list of numbers. Therefore, each item in the list can be processed by the lambda function in parallel. This is referred to as an embarrassingly parallel problem because there are NO data dependencies among the list items and the application of the lambda function.
Similarly, the lambda function in the reduce can execute over the data items in the list in parallel, but not to the same degree as the map, since it requires two data elements. Both of the following execution plans are valid for the reduce above, but one will have more parallelism than the other:
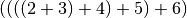
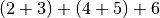
Notice in the second plan that the 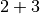 and
and 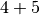 can execute in parallel.
can execute in parallel.
The functional programming model of mapReduce sums up the behavior of a mapReduce computation very nicely, from the programmer’s perspective. In fact, executing a massive mapReduce computation over thousands of compute nodes is essentially identical to executing the python program above, from the programmer’s point of view; all that is required is a mapper and a reducer, and the system will take care of the rest.
Extending the mapReduce Model to Massive Parallelism¶
Section Goals:
- Describe the basic architecture of a mapReduce system.
- Discuss the implications of adding/removing hardware to a mapReduce system.
- Describe the data model of a Mongo/BigTable/Hive type system.
Basic Big Data Concepts and Definitions¶
Big data is a general term applied to a large variety of situations, and with numerous definitions. In general, big data concepts tend to come into play when one or more of the three V’s of big data begin to be expressed in a particular problem or application. The three V’s of big data are:
- Volume: there is a lot of data. Typically things get interesting when the terabyte mark is exceeded, and get more interesting from there. Traditional databases and traditional data techniques can generally handle up to a TB of data without having to get too complex (in terms of guaranteeing uptime, data duplication and backups, and performance).
- Velocity: The data is generated, or arrives at the data center, very quickly. Anything that generates lots of data in a short time. For example, experiments in the Large Hadron Collider create up to PB of data in less than second. Facebook users are updating their accounts all the time.
- Variety: The data is not a fixed format, fixed size, or even consists of a fixed type of data. Traditional databases require the declaration of relations with explicit structure, and usually, fixed size records. This is impossible in many big data settings. Perhaps the data being stored evolves over time, perhaps the structure of records evolves over time, perhaps not all records are complete. The system must be able to not only handle such data, but must be able to query data in a variety of formats
Big data systems wrestle with problems of scale that are just not an issue in smaller systems. Systems may comprise thousands of nodes. Even if the nodes are expensive, server grade hardware, node failures are going to be a problem. Think about creating a new social networking application that stores user data. The company requires a lot of storage, to store a lot of data items that must be quickly retrievable, that must provide some guarantee that data will not be lost, and that must do all this on a budget. Thus, central design goals are typically to be:
- Scalable: be able to grow the systems with minimal configuration, and with heterogeneous hardware.
- Maintainable in the face of failures: if a node fails, the data stored on that node must already be duplicated or triplicated on other nodes, and the system should notice when nodes fail and make sure all data that was stored on that node is sufficiently replicated on other nodes. This must be done automatically.
- Use commodity, heterogeneous hardware: nodes need to be flexible, the system should be able to grow without upgrading existing nodes if desired.
- Provide fast query and retrieval: the system needs some query mechanism that is highly parallel, flexible, and relatively easy to use. Furthermore the queries must be able to possibly return huge results (more data than can fit on a single node, possibly).
To achieve these goals, big data systems have traditionally been designed as a distributed file system combined with a query mechanism
Google File System (GFS)¶
GFS was what really got the whole big data thing going on a large commercial scale. The idea was to create a file system that can expand over multiple nodes (thousands) automatically, can automatically incorporate new nodes and identify and de-incorporate faulty nodes, and can handle huge volumes of data.
Remember the Google application area. Web pages are crawled and stored on Google servers. The term crawled means that a copy of the web page is downloaded to the Google servers, and all the links on that page are stored so that they can be downloaded as well. The downloaded web pages are then processed into a form that is easily queryable using massive parallelism. Crawlers are only so fast (see exercise below), and web pages need only be re-crawled so often (see exercise below), so the velocity of data coming into the servers is not necessarily huge. But, they are keeping a copy of the Internet, so volume is huge! Also, web pages are unstructured text, contain multimedia, etc., so variability is huge.
Exercise
Web crawlers are only so fast. What limits the speed of crawling the web? Think of the architecture of the Internet, the destination of all of those web pages that are crawled, bottlenecks, etc.
Web pages do not necessarily need to be re-crawled very often. What would be an exception to this rule? What are the consequences of re-crawling more often vs. less often.
Basic Architecture of the GFS (and other similar distributed file systems)¶
The architecture of GFS and other similar file systems (Hadoop), is best understood if considered in the context of the assumptions under which the systems are designed. These include:
- The system is built from inexpensive, failure-prone hardware.
- The system must be built from heterogeneous hardware. (the compute nodes do not need to be identical)
- The system must be easy to maintain. In other words, adding nodes or removing nodes should be easy. In fact, adding hundreds or thousands of nodes should require minimal software configuration.
- High bandwidth is more important than low latency. There are very few, stringent response time requirements.
So, the distributed file system should be easy to manage on the hardware side, and the mapReduce interface should make it easy to run massively parallel programs from the software side. In essence, everything should be easy. Think about this. A huge installation of such a file system may have thousands of inexpensive, failure-prone nodes; therefore, at any given time, at least one node may be broken. If adding a node to, or removing a node from, a system required significant hardware and software configuration, the costs of paying people to do this would become prohibitive at large scales. Also, nodes may not be able to be replaced before another node breaks, meaning that the system is always running below peak capacity.
To achieve these goals, the architecture is remarkably simple. In its most basic form, such a distributed file system contains 1 master node, and many file server nodes. The master node basically keeps track of which file servers contain the files stored in the system. When a piece of information (lets say a copy of a webpage) needs to be inserted into the system, the master node checks to see which file servers have space for it. The master node then sends the file containing the web page to 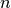 file servers where is the desired amount of duplication. The file servers simple store the file.
file servers where is the desired amount of duplication. The file servers simple store the file.
The assumptions 1,2, and 3 are all satisfied by this basic architecture. Note that no hardware or software requirements are imposed on the master or file servers. The only requirement is that the GFS code be installed. There is no requirement for servers to be identical, or have any special features. Finally, data is stored on different physical servers. Lets assume 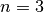 , all data is stored in triplicate. If one server containing a particular piece of data breaks and stops responding, the master will notice this, and realize it only has two copies of all data that was stored on that server. The master will instruct the file servers that contain other copies of that data to copy that data to another file server so that data is then, again, stored in triplicate. If a new node is added to the system, the master must simply be told of its existence, and it automatically begins to use it. Clearly, such a file system enables relatively easy management of a huge number of servers.
, all data is stored in triplicate. If one server containing a particular piece of data breaks and stops responding, the master will notice this, and realize it only has two copies of all data that was stored on that server. The master will instruct the file servers that contain other copies of that data to copy that data to another file server so that data is then, again, stored in triplicate. If a new node is added to the system, the master must simply be told of its existence, and it automatically begins to use it. Clearly, such a file system enables relatively easy management of a huge number of servers.
There is one more piece to the architecture, and that is the client. Essentially, a client is written to execute a particular type of query. For example, lets say that a common query will be to count the number of web pages that contain the word cat. However, we want to generalize this so that we can count the number of web pages that contain any user specified word. A programmer can write a client that will do the following:
- Get a query word from the user. Lets call this
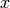 .
. - The client will go to the master node to find out which web pages are stored in the system and which file server each web page is on. The client will then go to each file server it needs to visit, read the web page, and count it if it contains the word provided by the user.
- The client will sum the results into a final count.
The important point to notice is that once a client is created, any user can simply use the client. This makes querying the system super easy if the appropriate client exists. Most file systems of this type contain a mapReduce client.
Finally, notice that since the data is on independent servers, all servers can be accessed in parallel. In the example where we count the number of web pages containing the word cat, each server can compute a count independently, and the counts for various servers can then be merged (If you look back at the Python map reduce example, you should be able to see how a mapper can be applied to each server independently, and results from each server get summed in a reducer!)
Using a mapReduce Client¶
To execute a mapReduce query, we assume that we have a working Hadoop/GFS/other system set up that provides a mapReduce client. Each system will have its own specifics over how we need to write our query, but in general, they all follow the same form:
- We need a map function that will be executed on every file in the system. That function will emit a key,value pair to the client. The client will automatically group values together with matching keys.
- We need a reduce function that will accept a key, and an array of values that were emitted with that key from the mapper. The reducer will then perform some computation, and return another key,value pair. Again, the client will store those in the system.
- The result is a file containing a bunch of key,value pairs.
Example
Map and reduce functions have the following signatures:
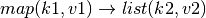
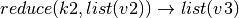
So, constructing mapReduce queries is easy for the programmer, just make 2 functions and don’t worry about parallelism or synchronization. The client takes care of that for you.
Lets look again at an example similar to the cat counting example. In this example, lets assume we want to find the number of times ALL words occur in our data set:
Example
Assume we have a working distributed file system that provides a mapReduce client. Further, we are storing files in the file system such that each file contains the contents of a web page, and the file name of each file is the URL of the web page. If we want to write a mapReduce query to count the number of times all words appear in those web pages, we could write the following query:
(note that this is a common example query used in [GFS2003] and other places)
map(String key, String value):
// key: file name
// value: file contents
for each word w in value:
EmitIntermediate(w, "1");
reduce(String key, Iterator values):
// key: a word
// values: a list of counts
int result = 0;
for each v in values:
result += ParseInt(v);
Emit(AsString(result));
Getting MongoDB Up and Running¶
In this module, we use MongoDB as an example for a few reasons:
- It is open source and freely available.
- It is available on a variety of platforms.
- A basic, yet usable, installation requires almost no configuration.
- It can scale easily across multiple file servers, or run on a single machine.
- The mapReduce functions are written in javascript, a language that is somewhat accessible to novice programmers.
- MongoDB is lightweight enough that students can install and use an instance on their own laptops/desktops.
Here, we will briefly list the steps to install MongoDB on a working Linux server. The MongoDB website has excellent documentation for installing a basic MongoDB instance on a variety of platforms. If you are an instructor, your Instructional Technologies Support office should be able to provide you with a basic Linux server and user accounts for your students. This tutorial uses the Ubuntu package manager, you will need to adapt to your own Linux distribution.
Once you have a Linux server, you need to install the MongoDB system:
user@server/~$ sudo apt-get install mongodb
[sudo] password for user: [enter your password]
The above commands will install a basic 1 node MongoDB on your computer. At this point, you may need to start the MongoDB, but most package managers will take care of this for you. If there is trouble, check the MongoDB website tutorials for help.
At this point the MongoDB instance is avaialable to ALL users on the system. To enter the command line interface to the database, you simply type mongo. The MongoDB instance can contain multiple databases. Each database will have a name, and will contain collections of documents. To see the databases currently housed in your MongoDB instance, try the following:
user@server/~$ mongo
MongoDB shell version: 2.4.9
connecting to: test
> show dbs
local 0.078125GB
> quit()
The mongo command starts the MongoDB shell, which you can use to execute commands on the database. MongoDB automatically connects the test database (if that database does not exist, it will be created once you create a collection and documents in it). The show dbs command shows all the databases currently housed in the MongoDB instance. The local database is created by MongoDB and Mongo uses it for bookkeeping purposes. Each line beginning with a > is a command prompt. The quit() command allows you to exit the MongoDB instance
Security Note!!
By default, ALL users that have access to the Linux server effectively have administrator privileges on the MongoDB instance. There are ways to limit this, but for the purposes of class assignments, it is not really necessary. However, you need to emphasize to students that they should create databases with names that are unique (preface the name with your student ID number, for example) so they do not accidentally clobber each other’s databases. Also, students should be instructed not to delete other student’s databases!!
The MongoDB Data Model¶
As we mentioned earlier, a MongoDB instance contains many databases. One database contains many collections. A collection contains many documents. The document is the primary mechanism of structuring data in MongoDB.
Mongo documents are simply JSON types. JSON is a text based data representation that allows a user to define structure in data, but does not impose structure on data. It is basically a list of labels and values:
Example of a JSON document
Lets say I want to create a document that describes a grocery store. In fact, I am trying to keep a database of grocery stores, so each document will contain information about 1 grocery store. A simple example might be:
{
"name" : "Superman's Supermarket:,
"address" : "123 Super St.",
"NumberOfEmployees" : 20
}
Now, lets say that I want to add something a bit more complex. We need to keep track of a store’s specialty items, but a store may have more than 1 specialty item, or none at all. The nice thing about a JSON document is that a JSON document can be a value in a JSON document. Lets create a competitor’s store:
{
"name" : "Batman's Supermarket:,
"address" : "123 Bat Cave Rd",
"NumberOfEmployees" : 15,
"SpecialItems" : {
"Fruit" : "blueberries",
"PetFood" : "Bat Chow"
}
}
The specialItems label contains an entire sub-document. In general, any document can contain a subdocument, which can contain a subdocument, etc. See http://json.org/ for all the details of JSON.
One thing to note is that a Mongo collection is defined as containing documents, meaning, any document is fine. In the example above, both documents can be stored in the same collection, despite having different structure, different labels, different size, etc. In fact, Mongo enforces NO constraints on the documents by default. If you create 100 documents each representing a supermarket, they are not required to share even a single label!
Concept
Because no constraints on the type, structure, or size of documents in a collection are enforced by default, it is up to the user to know the structure of the documents they are querying (or least have the ability to find out the structure).
Loading a Data Set Into MongoDB¶
Section Goals
- Gain basic skills in: loading a data set into MongoDB.
At this point, any user with access to the server on which the MongoDB instance is installed can log into the server, and then manipulate create/delete/query data on the MongoDB instance. Lets assume a student, Alice, is going to load some data for an assignment. For this tutorial, we have provided a data file consisting of on-time-statistics for airlines in the United States. This data set is freely available from here: http://www.transtats.bts.gov/OT_Delay/OT_DelayCause1.asp A copy of the data containing entries ranging from 1987 -2014 is provided: airlineDelay.csv (30MB file!). We have made modifications to the raw data in 3 places: some of the entries in the raw data had blank values that were confusing the CSV file reader, so we modified those 3 lines so that the CSV file reader could read the data to load it into MongoDB. No data was added or removed, we simply changed the number of commas on those 3 lines.
To load the data set, you first need to get the airlineDelay.csv file onto the server where MongoDB is installed. It may be useful for the instructor to put the file in a world-readable directory on the server.
To create a database, enter the mongo shell and type: use [your DB name]. Again. . . all users have root access to the mongo database (although not to the sever). This means you have the ability to alter/destroy any data in the mongo system, including the data belonging to other students. Don’t be mean, don’t mess with other people’s data, don’t waste anybody’s time. Everyone should create their own database and call it something unique; for example, your user name. Within your own database, you can create as many collections as you like.
To load the flight data into your database, use the following command from the command line (NOT the mongo shell!!) (replace [your DB name] with the name of your database within mongo. It will add the data to the collection called delayData):
user@server/~$ cd example
user@server/~/example$ ls
airlineDelay.csv
user@server/~/example$
user@server/~/example$ mongoimport -d userDB -c delayData --type csv --file airlineDelay.csv --headerline
connected to: 127.0.0.1
Thu Oct 16 10:07:43.007 Progress: 7483974/30791275 24%
Thu Oct 16 10:07:43.014 42000 14000/second
Thu Oct 16 10:07:46.010 Progress: 14274866/30791275 46%
Thu Oct 16 10:07:46.010 80200 13366/second
Thu Oct 16 10:07:49.011 Progress: 21239882/30791275 68%
Thu Oct 16 10:07:49.012 119600 13288/second
Thu Oct 16 10:07:52.007 Progress: 26615020/30791275 86%
Thu Oct 16 10:07:52.007 150000 12500/second
Thu Oct 16 10:07:53.822 check 9 173658
Thu Oct 16 10:07:54.664 imported 173657 objects
user@server/~/example$ mongo
MongoDB shell version: 2.4.9
connecting to: test
> show dbs
local 0.078125GB
userDB 0.453125GB
> quit()
Now, you have a database called userDB containing 173,657 documents taking up 0.078GB of space. This is not exactly huge data, but its big enough to practice with. Also, this is a real data set that you can use to learn about the real world!
Warning
Don’t Be Mean!!
Remember, every user should create a unique name for their database, and NOT interfere with anyone else’s database. One positive note is that if the MongoDB instance gets mangled, its very easy to delete the whole thing, re-install, and reload the data as we just did.
Basic MongoDB Queries to Explore Your Data Set¶
Section Goals
- Gain basic skills in: using the command line interface for MongoDB and performing basic queries to explore aspects of that data set.
Each entry in the airline delay database represents the aggregate monthly data for a particular airline at a particular airport. For example, one entry might be the delay information for Southwest Airlines at St Louis Airport during December 2013.
Each entry lists the number of flights, the number of flights delayed (15 minutes beyond the scheduled arrival time), the number of flights canceled and diverted, the minutes of delay due to carrier delay - weather delay - national air system delays - security delay. The _ct fields list the count of flights experiencing each delay (they add up the arr_del15 column). Because a flight can have multiple delay types, these numbers are real numbers. For example, if a flight was 30 minutes late, 15 minutes due to weather and 15 minutes due to security it will contribute .5 to weather_ct and .5 to security_ct. It will also contribute 15 to the weather_delay field and 15 to the security_delay field.
Finally, the arr_delay column is the sum of total delay minutes for the document (that is … arr_delay = carrier_delay+ weather_delay + nas_delay + security_delay + late_aircraft_delay)
The names of each field in an entry:
| Label/field name | Meaning |
|---|---|
| year | The year the month occurred |
| month | The month for which data was collected |
| carrier | The airline code |
| carrier_name | The airline name |
| airport | The airport code |
| airport_name | The airport name |
| arr_flights | # of flights that arrived at the airport |
| arr_del15 | # of flights that arrived >= 15 minutes late |
| carrier_ct | # of flights delayed due to the carrier |
| weather_ct | # of flights delayed due to weather |
| nas_ct | # of flights delayed due to national air system |
| security_ct | # of flights delayed due to security |
| late_aircraft_ct | # flights delayed because a previous flight using the same aircraft was late |
| arr_cancelled | # of canceled arrivals |
| arr_diverted | # of scheduled arrivals that were diverted |
| arr_delay | Sum of the delay minutes |
| carrier_delay | Total minutes of delays due to carriers |
| weather_delay | Total minutes of delays due to weather |
| nas_delay | Total minutes of delays due to natl. air service |
| security_delay | Total minutes of delays due to security |
| late_aircraft_delay | Similar to late_aircraft_ct. The total minutes of delay due to a previous flight using the same aircraft arriving late. |
The JSON document structure for an individual document is shown by looking at a single imported document (1 row from the database). The following shell sequence shows how to use a command to see 1 document in a collection. Always remember to first switch to the database you want to use, then explore the collections. In this example, the database is named airline and the collection is delays:
user@server/~/example$ mongo
MongoDB shell version: 2.4.9
connecting to: test
> use airline
switched to db airline
> show collections
delays
system.indexes
> db.delays.findOne()
{
"_id" : ObjectId("526ea45fe49ef3624c73e94f"),
"year" : 2003,
" month" : 6,
"carrier" : "AA",
"carrier_name" : "American Airlines Inc.",
"airport" : "ABQ",
"airport_name" : "Albuquerque, NM: Albuquerque International Sunport",
"arr_flights" : 307,
"arr_del15" : 56,
"carrier_ct" : 14.68,
"weather_ct" : 10.79,
"nas_ct" : 19.09,
"security_ct" : 1.48,
"late_aircraft_ct" : 9.96,
"arr_cancelled" : 1,
"arr_diverted" : 1,
"arr_delay" : 2530,
"carrier_delay" : 510,
"weather_delay" : 621,
"nas_delay" : 676,
"security_delay" : 25,
"late_aircraft_delay" : 698,
"" : ""
}
>
View documents in a collection
Assume a collection named delays in a selected database.
To view a single document in a collection, use:
> db.delays.findOne()
To view multiple documents in a collection, use:
> db.delays.find()
Constructing MapReduce Queries on Your Data Set¶
Section Goals
- Be able to construct and execute a mapReduce program on MongoDB
- Be able to perform queries to explore the result of a mapReduce query.
MongoDB provides a mapReduce client to execute queries across a database. If we only have a 1 node instance, then clearly there will be no parallelism across machines; however, recall that the nice thing about the mapReduce model and its associated distributed file systems is that we can easily add more machines to achieve more parallelism, and not have to change our queries at all to take advantage of it!
Mongo uses javascript to represent mapReduce queries. This is nice because javascript is generally easy to use, and provides just about everything you need as built in functions/libraries/types. It is also rather readable. If you have never used javascript, you will see that in the following examples that it will be somewhat intuitive for our uses.
The general prototype of a mapReduce operation in Mongo is the define a mapper function and reducer function, then use the mapReduce client (implemented as a Mongo function) to execute the query using the specified functions. For example:
Mongo mapReduce Prototype
The following code creates a mapper function named mapper1 and a reducer function named reducer1. The result of the mapReduce operation will be a mongo collection named OUTPUT_COLLECTION_NAME.
var mapper1 = function() {
YOUR CODE HERE
emit( "SOMEKEY", SOMEVALUE );
};
var reducer1 = function( keyval, areasArray ) {
YOUR CODE HERE
return ( SOMEVALUE );
};
db.test.mapReduce( mapper1, reducer1,{out:"OUTPUT_COLLECTION_NAME"} )
db.OUTPUT_COLLECTION_NAME.find()
Note that the reducer does not explicitly return a key value. The key value passed to the reducer will automatically be associated with the value returned from the reducer by the mapReduce client.
Lets take a look at an actual query over the airline statistics data set. We will begin with a basic query that finds the airport in the united states that has had the most number of diversions throughout the entire data set. For each document in our collection, we will be concerned with 2 pieces of data:
- The name of the airport:
airport_name - The number of flights diverted from that airport:
arr_diverted
Remember, that each document contains the data for a particular airline at a particular airport during a particular month. So, for the St. Louis Airport during January 2014, there will be a document containing statistics for Southwest Airlines, another document for Delta Airlines, another document for United Airlines, etc.
In order to construct the result for our query, we basically need to construct a collection containing a single JSON document for every airport in our data set. The document needs to contain the name of the airport, and the number of flights diverted from that airport. So, we need to transform the set of documents in our database into the desired set of documents containing the answer. All the data is in the database, it is just not is in a format in which the answer is readily available. We will use a mapReduce job to make this transformation.
Example: Find the airport with most number of diversions.
- A document contains data for 1 airline at 1 airport during 1 month. We need to extract the data we need from each document. The mapper will do this:
var m1 = function(){
emit( this.airport_name, this.arr_diverted );
};
NOTE the this keyword. A mapper is applied to every document in the data set. The this keyword allows us to access data from the document. this.airport_name retrieves the airport name from the document.
Recall that when we emit a value, the mapReduce client will automatically group all values with a matching key together into a list. So, the end of the mapper stage will result in a list of keys; each key will be associated with a list of values that were emitted with that key. For example, if there were 3 documents in the database indicating that STL had 3 diversions in January, STL had 2 diversion in February, and HOU had 7 diversion in January. In short, assume the following JSON documents in the delayData collection:
{
"airport_name" : "STL",
"year" : "2012",
"Month" : "January",
"arr_diverted" : "3"
}
{ "airport_name" : "STL",
"year" : 2012,
"Month" : "February",
"arr_diverted" : 2
}
{ "airport_name" : "HOU",
"year" : 2012,
"Month" : "January",
"arr_diverted" : 7
}
Then, at the end of the emit stage the mapReduce client would construct the following lists:
| Key | Value List |
|---|---|
| STL | [3,2] |
| HOU | [7] |
The job of the reducer is now to reduce those lists into a meaningful result. Conceptually, a reducer will be run for each key. In practice, this is not necessarily true, as the system can take advantage of parallelism to schedule a more efficient execution plan (See the reducer example in Python up at the beginning). So, in concept, a reducer simply reduces all the values for a particular key into a single, meaningful, value. Remember, we want the total number of diversions for our airports.
The following reducer will sum up all the values in the list associated with a key. It will then return the sum. Notice the function Array.sum(); this is provided by javascript. You can always explicitly write a loop to compute the sum.
NOTE: the reducer does not explicitly emit a key,value pair. In Mongo, whatever value is in the return statement will be associated with the key passed into the function.
var r1 = function( key, valArr ) {
return Array.sum( valArr );
}
Once the reducer is run, we should end up with the following keys and values:
| Key | Value List |
|---|---|
| STL | [5] |
| HOU | [7] |
Finally, we have defined the map and reduce functions. Now we must actually execute them. To begin a mapReduce client with the above mapper and reducer, we use the following code.
db.delayData.mapReduce( m1, r1, {out:'tmp'});
The {out:'tmp'} simply means that the collection containing the result of our query will be named tmp.
The last step is to look at the result. Remember, we wanted to find the airport with the most diversions, but our query just returned the number of diversions from ALL airports. The easiest way to find our answer at this point is to just sort the results. Mongo uses the find() function to return documents in a collection. Mongo also provides a sort() function to sort the documents in a collection. The following lien will sort the documents in the tmp collection in descending order and print them to the screen.
db.tmp.find().sort( {value:-1} )
All together, you can copy and paste the following code into the Mongo shell to execute the operations and view the results. Remember, this code assumes the data is in a collection called delayData. Replace delayData with whatever collection your data is in:
var m1 = function(){
emit( this.airport_name, this.arr_diverted );
};
var r1 = function( key, valArr ) {
return Array.sum( valArr );
}
db.delayData.mapReduce( m1, r1, {out:'tmp'});
db.tmp.find().sort( {value:-1} )
A script of the execution is shown below. Note that because we don’t want to make anyone angry at our tutorial, we will show the airports with the LEAST number of diversions. Generally, this means the airports are either:
- Not receiving many commercial flights.
- Small (and don’t get a lot of flights).
- So remote that aircraft cannot divert because there is no place to divert to (the scarier option).
- Do not report data for some reason.
user@server/~/example$ mongo
MongoDB shell version: 2.4.9
connecting to: test
> show dbs
local 0.078125GB
userDB 0.453125GB
> use userDB
switched to db userDB
> show collections
delayData
system.indexes
> var m1 = function(){
... emit( this.airport_name, this.arr_diverted );
... };
>
> var r1 = function( key, valArr ) {
... return Array.sum( valArr );
... }
>
> db.delayData.mapReduce( m1, r1, {out:'tmp'});
{
"result" : "tmp",
"timeMillis" : 4565,
"counts" : {
"input" : 173657,
"emit" : 173657,
"reduce" : 16838,
"output" : 363
},
"ok" : 1,
}
> show collections
delayData
system.indexes
tmp
> db.tmp.find().sort( {value:1} )
{ "_id" : "Clarksburg/Fairmont, WV: North Central West Virginia", "value" : 0 }
{ "_id" : "Columbus, MS: Columbus AFB", "value" : 0 }
{ "_id" : "Dickinson, ND: Dickinson - Theodore Roosevelt Regional", "value" : 0 }
{ "_id" : "Greenville, MS: Mid Delta Regional", "value" : 0 }
{ "_id" : "Guam, TT: Guam International", "value" : 0 }
{ "_id" : "Gustavus, AK: Gustavus Airport", "value" : 0 }
{ "_id" : "Iron Mountain/Kingsfd, MI: Ford", "value" : 0 }
{ "_id" : "Kansas City, MO: Charles B. Wheeler Downtown", "value" : 0 }
{ "_id" : "Moses Lake, WA: Grant County International", "value" : 0 }
{ "_id" : "Pago Pago, TT: Pago Pago International", "value" : 0 }
{ "_id" : "Palmdale, CA: Palmdale USAF Plant 42", "value" : 0 }
{ "_id" : "Phoenix, AZ: Phoenix - Mesa Gateway", "value" : 0 }
{ "_id" : "Saipan, TT: Francisco C. Ada Saipan International", "value" : 0 }
{ "_id" : "Salem, OR: McNary Field", "value" : 0 }
{ "_id" : "Staunton, VA: Shenandoah Valley Regional", "value" : 0 }
{ "_id" : "Visalia, CA: Visalia Municipal", "value" : 0 }
{ "_id" : "Yakima, WA: Yakima Air Terminal/McAllister Field", "value" : 0 }
{ "_id" : "Del Rio, TX: Del Rio International", "value" : 1 }
{ "_id" : "Houston, TX: Ellington", "value" : 1 }
{ "_id" : "North Platte, NE: North Platte Regional Airport Lee Bird Field", "value" : 1 }
Type "it" for more
>
That was a long example, but it hits all the high points.
The next example emphasizes the fact that not documents must emit a value. For example, if we only want to find the number of diversions occurring at airports in 2012, we must only emit values from documents indicating that they have data for 2012. The following code changes the previous example slightly to accomplish this:
var m1 = function(){
if( this.year == 2012) {
emit( this.airport_name, this.arr_diverted );
}
};
var r1 = function( key, valArr ) {
return Array.sum( valArr );
}
db.delayData.mapReduce( m1, r1, {out:'tmp'});
db.tmp.find().sort( {value:-1} )
Finally, part of the power of mapReduce is that the key does not have to be a basic data type. In the Mongo system, this means that they key can be a JSON document. In generel, in other systems implementing a mapReduce framework, this means the key can be almost any complex grouping of data items.
For example, if we want to find the number of flight diversions that occur in St Louis, but we want to group them according to year, then we must construct our key to include the airport name and the year. Furthermore, we only emit such a key if the airport name is STL. The following example does this.
Example: Document as a Key:
Assume the following JSON documents in the delayData collection:
{ "airport_name" : "STL",
"year" : 2012,
"arr_diverted": 3
}
{ "airport_name" : "STL",
"year" : 2012,
"arr_diverted": 5
}
{ "airport_name" : "STL",
"year" : 2011,
"arr_diverted": 7
}
{ "airport_name" : "HOU",
"year" : 2012,
"arr_diverted": 7
}
The mapper must construct a key for each input document consisting of a JSON document that contains the airport name and year:
var m1 = function(){
var rval = { airport: this.airport_name,
year: this.year };
if( this.airport=="STL") {
emit( rval, this.arr_diverted );
}
};
var r1 = function( key, valArr ) {
return Array.sum( valArr );
}
db.delayData.mapReduce( m1, r1, {out:'tmp'});
db.tmp.find().sort( {'_id.year':-1} )
The mapper will return process each document, emitting keys and values. The mapReduce client will then construct the following lists associated with keys:
| Key | Value list |
|---|---|
| {“airport”:”STL”, “year”:2012} | [3,5] |
| {“airport”:”STL”, “year”:2011} | [7] |
Finally, the reducer will sum the lists it is given and return the results to the tmp collection.
Exercises¶
- Query1: Find the total amount of delay minutes in the database (1 number).
- Query2: Find the total amount of delay minutes grouped by airline.
- Query3: Find the airport with the most canceled flights (this may require 2 map reduces, one to group the airports by their canceled flights, and another to find the airport with the most).
- Query 4: Find the airport with the most canceled flights in 2012.
- Query 5: Find, for each airline, the airport at which they have the most number of delays (use the arr_del15 column).
- Query 6: Find the average delay time for the airport with the most flights in the database.
- Query 7: For each airline, find the delay category that makes up the smallest amount of time of their delays, and then find the airport for which they have the most minutes of that delay category.
Hint for Query 7: One way to answer this will require 3 separate sets of map/reduce functions, 1 of those sets will get called in a loop:
step 1. get the correct category of delay for each airline
step 2. get the airline, airport, and sum of delays of the correct category for each airline/airport combo. This is where you probably need to execute map/reduces in a loop, once for each airline. Check out the ‘scope’ parameter to the db.mapReduce() function
step 3. find the airline/airport combo with the max number of delay minutes
Quick MongoDB Command Cheat Sheet¶
projection: ( the second argument ) >db.delays.find({},{weather_delay:1})
count docs in a collection: >db.runCommand({count:’delays’})
create database: > use mydb
drop database > use mydb; > db.dropDatabase();
list databases: > show dbs
drop collection: > db.collection.drop()
list a documents: > db.plots.findOne()
list all documents: > db.plots.find()
find price equal: > db.plots.findOne({price: 729})
find price greater than > db.plots.findOne({price: {$gt:729, $lt: 800}})
| [GFS2003] | (1, 2) Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung. 2003. The Google file system. In Proceedings of the nineteenth ACM symposium on Operating systems principles (SOSP ‘03). ACM, New York, NY, USA, 29-43. DOI=10.1145/945445.945450 http://doi.acm.org/10.1145/945445.945450 |