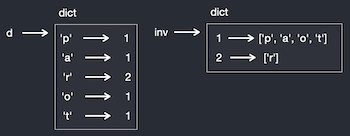
Here is the state diagram of the dictionary and the inverted dictionary.
Dictionaries are one of the best features Python has to offer. They act as the building blocks for many efficient and elegant algorithmic solutions.
Map, hash table, associative array are other common names used in other languages to describe the same concept.
A dictionary is a collection of key:value pairs, collectively known as items.
A key can be any immutable type, while the value it maps to can be of any type.
A dictionary is very efficient at retrieving a value given its key.
The keys are unique, so no duplicates are allowed.
You can create a dictionary using the dict() function or its shortcut notation using {}.
d1 = dict()
d2 = {}
print(d1, d2)
{} {}
You can initialize a dictionary when you create it by proviing key:value pairs.
en2sp = {'one': 'uno', 'two': 'dos', 'three': 'tres'}
print(en2sp)
{'one': 'uno', 'two': 'dos', 'three': 'tres'}
en2sp['four'] = 'quatro'
print(en2sp)
{'one': 'uno', 'two': 'dos', 'three': 'tres', 'four': 'quatro'}
Since version 3.7 dictionary order is guaranteed to be insertion order.
Traditionally a mapping structure is unordered.
To access an item use [], with the key as its argument. If the key is not found an error will occur.
print(en2sp['one'])
print(en2sp['ten'])
uno
--------------------------------------------------------------------------- KeyError Traceback (most recent call last) /var/folders/_5/pbybv9c90j77vqh9wby2v8140000gq/T/ipykernel_32281/4224520993.py in <module> 1 print(en2sp['one']) ----> 2 print(en2sp['ten']) KeyError: 'ten'
Use the len() function to find out how many elements a dictionary holds.
print(len(en2sp))
4
The in operator checks for key containment, i.e. if a key is present.
print('one' in en2sp)
print('uno' in en2sp)
True False
The question often is whether a given value is within the dictonary. For that use the values() function along with the in operator.
print('uno' in en2sp.values())
True
Recall, a dictionary is great for locating keys quickly and efficiently.
The reason has to do with its internal structure as a hash table. Basically, each key search takes the same amount of time no matter how many items are in the dictionary.
Searching a list on the other hand will depend on its length, since each element is searched in order. Thus, accessing the first element will take less time than accessing the last.
We say that a dictionary search is O(1), denoting constant time, while a list search is O(n) denoting a linear time. O here refers to the growth Order of time propotional to size.
The concept of algorithm analysis is studied elsewhere.
If I ask you to count how many times each character appears in a string, such as 'Hello there.' how would you go about it?
Let's examine some options:
Use 26 variables, each acting as a counter for each letter as you traverse the string.
Use a list, each element holding a count. Map each character to its index using ord(), i.e. ord('A') returns 65 which is 'A's ASCII value.
Use a dictionary with the key representing the character and the value its count. Add a newly found character with a count of 1, else increment the count of an existing character.
Although each does the same thing, each is implemented differently and offers different advantages.
Both the variable and list options require knowledge of the characters used in order to create appropriate counters. The list however may waste elements for those characters that don't appear in the string, since they would still be part of the setup.
A dictionary on the other hand is more efficient in this regard, since we would only add the characters we encounter, not to mention the efficient access to each.
The function histogram() below returns a dictionary with the character frequencies. That is what a histogram is in essence; a collection of frequencies (counters).
def histogram(s):
'''Returns a dictionary of character frequencies.'''
d = {}
# Traverse each character.
for c in s:
if c not in d:
# Add the new character to the dictionary.
d[c] = 1
else:
# Increment existing character's count.
d[c] += 1
return d
h = histogram('Hello there.')
print(h)
{'H': 1, 'e': 3, 'l': 2, 'o': 1, ' ': 1, 't': 1, 'h': 1, 'r': 1, '.': 1}
A dictionary offers the get() method that takes a key and a default value. The idea is that if the key exists, its value is returned, else the default value is returned instead.
Let's rewrite the histogram function above to make use of this method and simplify the code in the process.
def histogramGet(s):
d = {}
for c in s:
d[c] = 1 + d.get(c, 0)
return d
print(histogramGet('Hello there.'))
{'H': 1, 'e': 3, 'l': 2, 'o': 1, ' ': 1, 't': 1, 'h': 1, 'r': 1, '.': 1}
The function still traverses the string as before, but the conditional logic is now removed.
Line 4 uses the get() method to add 1 to the current count of a contained character or 0 otherwise.
Use a for along with in to traverse each key.
def printHistogram(h):
for key in h:
print(key, h[key])
printHistogram(h)
H 1 e 3 l 2 o 1 1 t 1 h 1 r 1 . 1
If you want to display the keys in sorted order, use the sorted() function.
def printSortedHistogram(h):
for key in sorted(h):
print(key, h[key])
printSortedHistogram(h)
1 . 1 H 1 e 3 h 1 l 2 o 1 r 1 t 1
A direct lookup is easy. Given a key k and a dictionary d, then its value can be accessed with v = d[k].
The interesting question is "If I have a value, what is its key?".
This is a bit tricky since multiple keys may map to the same value. Remember, keys are unique, not the values.
So, because of this fact, there is no easy reverse lookup. You will have to search.
def reverseLookup(d, val):
'''Finds the first key with the specified value.'''
for key in d:
if d[key] == val:
return key
# Did not find the value, so raise error.
raise LookupError("value not found in the dictionary")
# Create a histogram for 'parrot'.
d = histogramGet('parrot')
# Find first key with count of 1.
print(reverseLookup(d, 1))
# Serch for non existing value.
print(reverseLookup(d, 3))
p
--------------------------------------------------------------------------- LookupError Traceback (most recent call last) /var/folders/_5/pbybv9c90j77vqh9wby2v8140000gq/T/ipykernel_32281/2159562934.py in <module> 17 18 # Serch for non existing value. ---> 19 print(reverseLookup(d, 3)) /var/folders/_5/pbybv9c90j77vqh9wby2v8140000gq/T/ipykernel_32281/2159562934.py in reverseLookup(d, val) 7 8 # Did not find the value, so raise error. ----> 9 raise LookupError("value not found in the dictionary") 10 11 # Create a histogram for 'parrot'. LookupError: value not found in the dictionary
The raise statement is part of exception handling, and we shall look at that later.
Our histogram stores the frequency of occurrence of each letter. But, what if we were interested in the reverse, i.e. a list of all the letters with a given frequency.
Since a dictionary's value can be any type, we can use a list to hold all the letters that share the same frequency.
Let's look at how we can do this.
def invertDict(d):
'''Returns an inverted dictionary.
key: d[key], value: [key1, key2, ...]'''
inv = {}
# Traverse each original key.
for origKey in d:
# Save its value.
newKey = d[origKey]
if newKey in inv:
# If key exists, add value to list.
inv[newKey].append(origKey)
else:
# Else, add a new list.
inv[newKey] = [origKey]
return inv
print(d)
inv = invertDict(d)
print(inv)
{'p': 1, 'a': 1, 'r': 2, 'o': 1, 't': 1}
{1: ['p', 'a', 'o', 't'], 2: ['r']}
Here is the state diagram of the dictionary and the inverted dictionary.
A dictionary uses a hashtable and thus the keys must be hashable.
A hash function basically maps a key to an integer, which is then used to access a key:value pair.
As this mapping only works if the hash function produces the same integer for a given key, it stands to reason that if you change the key, the hash function will return a different integer. Well, that is not good.
So, a key has to be immutable for all this to work. Let's see what happens if it is not.
l = [1,2]
d[l] = 'no no'
--------------------------------------------------------------------------- TypeError Traceback (most recent call last) /var/folders/_5/pbybv9c90j77vqh9wby2v8140000gq/T/ipykernel_32281/1558489836.py in <module> 1 l = [1,2] ----> 2 d[l] = 'no no' TypeError: unhashable type: 'list'
A memo is a previously computed value that is stored for later use.
The fibonacci series is a good example of where we can make use of this idea. The larger the requested number the more duplication of terms exists.
Look at the call graph for fibonacci(4) to appreciate the unfortunate redundancy.
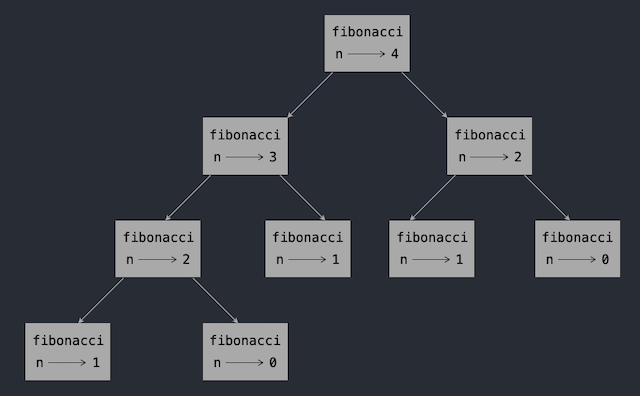
Since many terms are computed repeatedly (0, 1, 2...) we can use a dictionary to store each computed term the first time, and then simply retrieve it on subsequent calls.
Here's a memoised version of the fibonacci() function.
known = {0: 0, 1: 1}
def fibonacci(n):
'''Uses known memos to compute the nth fibonacci term.'''
if n in known:
return known[n]
else:
known[n] = fibonacci(n - 1) + fibonacci(n - 2)
return known[n]
print(fibonacci(6), known)
8 {0: 0, 1: 1, 2: 1, 3: 2, 4: 3, 5: 5, 6: 8}
known is created outside of the function, so it belongs to the __main__ frame. Another way to say this is that it is part of the main module's symbol table.
As such it is often called a global variable since it can be read from any function. To write to a global variable you must declare it inside a function with the global keyword, else a new local variable with the same name is created instead.
Let's look at this concept closely.
globalCount = 0
def f():
# Since we are 'writing' to the variable, a new local instance
# is created instead.
globalCount = 1
print('Before call:', globalCount)
f()
print(' After call:', globalCount)
Before call: 0 After call: 0
Notice how the global variable was superseded by a local variable of the same name, thus its value was never updated.
Now look at the next example that actually does update its value.
globalCount = 0
def g():
global globalCount
globalCount += 1
print('Before call:', globalCount)
g()
print(' After call:', globalCount)
Before call: 0 After call: 1
It should be noted that in Python everything is an object, and so variables are object references. So, if you have a mutable object, you can update the instance easily, as we saw with the known dictionary.
Create a separate Python source file (.py) in VSC to complete each exercise.
Download the file CROSSWD.TXT and rename it words.txt. This file includes official crosswords and you will need it for the exercises.
Write a function that reads the words in words.txt and stores them as keys in a dictionary. It doesn't matter what the values are. Then you can use the in operator as a fast way to check whether a string is in the dictionary or not.
Read the documentation of the dictionary method .setdefault() and use it to write a more concise version of the invertDict() function in this discussion.
Write a function named hasDuplicates() that takes a list as a parameter and returns True if there is any object that appears more than once in the list.
Use a dictionary for a fast version of this function.
Two words are rotate pairs if you can rotate one of them and get the other (Refer to p2: caesarCipher.py in the strings discussion).
Write a program that reads a wordlist and finds all the rotate pairs.