|
Parallel Plane Sweep
0.1
Shared memory multithreaded version of the plane sweep algorithm
|
|
Parallel Plane Sweep
0.1
Shared memory multithreaded version of the plane sweep algorithm
|
This documention describes code implementing a shared memory parallelization technique for the plane sweep algorithm. The implementation uses openMP for parallelization, and shows speedup roughly equal to half the number of cores available on a system.
This code includes two versions. One is a traditional plane sweep using an AVL tree for the active list and event queue. The second implementation is identical except that it uses a vector for the AVL tree and event queue. The vector version has time complexity 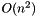 . The AVL version has time complexity
. The AVL version has time complexity 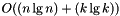 where
where 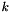 is the number of intersections.
is the number of intersections.
The code computes an overlay of two input regions. The halfsegments that are returned are labeled such that the intersection, union, or difference (or even topological predicates) can be extracted from the labels.
The data directory contains example input files.
Source code for the project is available at:
 1.8.10
1.8.10

