
For an input array of arbitrary integers (that is, we make no assumptions as to the range of the integers), Sum3 can be solved in 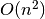 time using relatively simple algorithms.
time using relatively simple algorithms.
The purpose of this chapter is to emphasize the point that parallelism is not always the best solution to a problem. Sometimes, making algorithmic improvements (resulting in better theoretical complexity) can provide better speedups than parallelism; especially if you don’t have the hardware resources to take advantage of a parallel algorithm.
The easiest approach to code is to take advantage of hash tables. Hash tables are implemented in many languages, so they are cheap from a coding perspective, and they offer 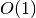 time for inserting an element and determining if an element is in the hash table ... under ideal circumstances. The approach is to:
time for inserting an element and determining if an element is in the hash table ... under ideal circumstances. The approach is to:
However, this approach suffers from some drawbacks. First, hash table operations can degrade to linear time under certain conditions (although this can be managed rather easily). Second, care must be taken to ensure that unique triples are identified. For example, if the input array was -2, 0, 4, one must ensure that -2+-2+4 = 0 does not get counted as a valid triple (since -2 only appears once in the input).
A slightly more complicated algorithm requires that the input array be sorted. The algorithm contains a loop that will traverse the input array from first to last.
Assume a sorted input array array containing n elements. We will first find all triples that add up to 0 and involve the first element in array. We set a=array[0]. A triple is then formed with b=array[0+1] and c=array[n-1]. If a+b+c > 0, then we need to reduce the sum to get it closer to 0, so we set c=array[n-2] (decrease the largest number in the triple to get a smaller sum). If a+b+c < 0, then we need to increase the sum to get it closer to 0, so we set b=array[0+2] (increase the smaller number to get a larger sum). This process continues until b and c refer to the same array element. At the end of this process, all possible triples involving the first array element have been computed.
To compute all triples involving the first array element, we took a pair of numbers from the array. After examining the pair, one number was excluded from further consideration in future triples involving the first array element. Therefore, for n array elements, we will construct n-2 triples due to the following: the first array element is used in every triple, leaving us to create pairs of the remaining n-1 elements; the first pair uses two elements and eliminates one from further consideration; all following pairs will reuse 1 element form the previous pair, and eliminate one element from consideration. Thus, computing all triples involving a single element requires 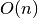 time. Repeating this for n elements in the input array requires time. A C++ implementation of this algorithm follows:
time. Repeating this for n elements in the input array requires time. A C++ implementation of this algorithm follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 | #include <iostream>
#include <sstream>
using namespace std;
int getRandInt( int *dataVec, int dataSize )
{
// load up a vector with random integers
int num;
for( int i = 0; i < dataSize; i++ ) {
// integers will be 1-100
num = rand() % 100+1;
if( rand( ) % 2 == 0 ) {
// make some integers negative
num *= -1;
}
dataVec[i] = num;
}
}
int main(int argc, char * argv[] )
{
int dataSize = 0;
if( argc < 2 ) {
std::cerr << "usage: exe [num of nums] [optional seed value]" << std::endl;
exit( -1 );
}
{
std::stringstream ss1;
ss1 << argv[1];
ss1 >> dataSize;
}
if( argc >= 3 ) {
std::stringstream ss1;
int seed;
ss1 << argv[2];
ss1 >> seed;
srand( seed );
}
else {
srand( 0 );
}
// create a data vector
int *data = new int[ dataSize ];
// load it up with random data
getRandInt( data, dataSize );
// sort the data
sort( data, data + dataSize );
// do the Sum3 computation. O(n^2)
int count = 0;
int a,b,c, sum; // array elements
int j,k; // array indices
for (int i = 0; i < dataSize-2; i++){
a = data[i];
j = i+1;
k = dataSize-1;
while( j < k ) {
b = data[j];
c = data[k];
sum = a+b+c;
if( sum == 0 ){
cerr << a << " " << b << " " << c << endl;
count++;
}
if( sum < 0 ){
j++;
}
else {
k--;
}
}
}
cout<< count <<endl;
|
}
One pitfall in this algorithm is that duplicate values cause problems.
Example
Consider the input string array = [-4, 1, 1, 3, 3]. There are 4 triples that sum to 0:
However, the above code will only find 2 triples. The algorithm progresses as follows, with items being examined in bold:
Effectively, the algorithm only finds triples involving the first 1, and none involving the second 1.
In fact, duplicates cause 3 problems that must be addressed:
The following program handles duplicates correctly. Problem 1 and Problem 2 are handled in a single conditional, the first if statement in the while loop. Note that when such a situation occurs, we have effectively found the point at which j and k converge, and so we break out of the while loop. Problem 3 is handled in the second if statement in the while loop; the modification of j and k are again handled specially in this situation (since they may be increased or decreased by more than 1). The third if statement in the while loop handles the situation in which duplicates do not occur. The final else block in the while loop handles the normal increment of j or decrement of k when a triple with a non-zero sum is visited. The complete solution for handling duplicates is:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 | #include <iostream>
#include <sstream>
using namespace std;
int getRandInt( int *dataVec, int dataSize )
{
// load up a vector with random integers
int num;
for( int i = 0; i < dataSize; i++ ) {
// integers will be 1-100
num = rand() % 100 +1;
if( rand( ) % 2 == 0 ) {
// make some integers negative
num *= -1;
}
dataVec[i] = num;
}
}
int main(int argc, char * argv[] )
{
int dataSize = 0;
if( argc < 2 ) {
std::cerr << "usage: exe [num of nums] [optional seed value]" << std::endl;
exit( -1 );
}
{
std::stringstream ss1;
ss1 << argv[1];
ss1 >> dataSize;
}
if( argc >= 3 ) {
std::stringstream ss1;
int seed;
ss1 << argv[2];
ss1 >> seed;
srand( seed );
}
else {
srand( 0 );
}
// create a data vector
int *data = new int[ dataSize ];
// load it up with random data
getRandInt( data, dataSize );
// sort the data
sort( data, data + dataSize );
// do the Sum3 computation. O(n^2)
int count = 0;
int a,b,c, sum; // array elements
int j,k; // array indices
for (int i = 0; i < dataSize-2; i++){
a = data[i];
j = i+1;
k = dataSize-1;
while( j < k ) {
b = data[j];
c = data[k];
sum = a+b+c;
if( sum == 0 && b == c ) {
// case where b == c. ie, -10 + 5 + 5
// or where a == b == c == 0
int num = k-j+1;
count += (num*(num-1))/2;
break;
}
else if( sum == 0 && (data[j+1] == b || data[k-1] == c )){
// case where there are multiple copies of b or c
// find out how many b's and c's there are
int startj = j;
while( data[j+1] == b ) j++;
int startk = k;
while( data[k-1] == c ) k--;
count += (j-startj+1) * (startk-k+1);
j++;
k--;
}
else if( sum == 0 ){
// normal case
count++;
j++;
} else {
// if sum is not 0, increment j or k
if( sum < 0 ) j++;
else k--;
}
}
}
cout<< count <<endl;
}
|
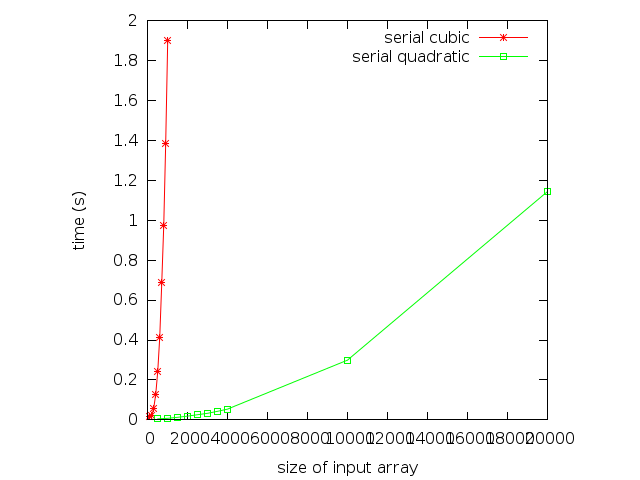
Here are some running times for the previous program:
| Array Size | Time (s) |
|---|---|
| 500 | .005 |
| 1000 | .008 |
| 1500 | .013 |
| 2000 | .019 |
| 2500 | .026 |
| 3000 | .033 |
| 3500 | .043 |
| 4000 | .054 |
| 10000 | .299 |
| 20000 | 1.142 |
Here we show the graph of running times for the cubic and quadratic versions of the algorithm. Notice the vast difference in running times for the two programs. Again, the cubic and quadratic nature of the algorithms are visible.
Exercise
Create a Makefile and use the Makefile to compile the program listed above. Run the program using the time command on linux to see some running times. Collect running times on two different machines. Write a brief report indicating your results and listing the machine specifications. List reasons why one machine is faster than the other.
To find out machine specs on linux, check out the lspci abd lscpu commands, and check out the /proc filesystem. Check the man pages and/or google for information on how to use/interpret these resources